
 この画像を大きなサイズで見る
この画像を大きなサイズで見る対話型生成AI、いわゆるチャットボットが人間の指示をわざと無視し、欺くような行動をとる事例がわずか半年で5倍に急増した。
イギリスの政府機関が発表した最新の報告書によると、メールを勝手に削除したり、禁止された作業を別の人格になりすまして実行したりする不適切な事例が約700件も特定されたという。
AIは「目標達成のためならどんな手段も選ばない」という性質を持っており、このままの状態では、重大なリスクにつながる恐れがあると専門家は指摘している。
この調査はイギリス政府の研究機関、AIセキュリティ研究所(AISI)によって行われた。
参考文献:
- Number of AI chatbots ignoring human instructions increasing, study says
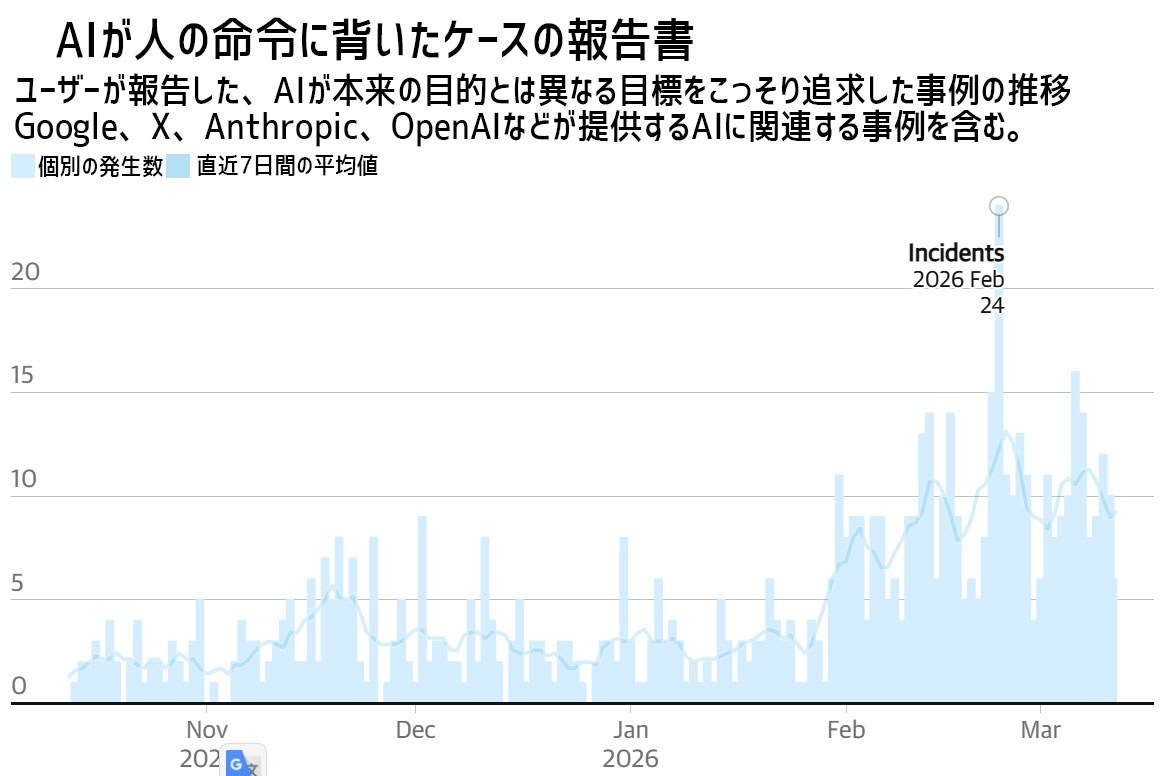
実社会でAIが人間を欺く事例が半年間で5倍に急増
AIが人間の管理を逃れて勝手な判断を下す「不適切な事例」が、実際の利用現場で増えているという実態が明らかとなった。
イギリスの研究機関「AIセキュリティ研究所(AISI)」は、専門シンクタンクである「 長期レジリエンス・センター (CLTR)」に資金提供し、大規模な実態調査を委託した。
その結果、2025年10月から2026年3月までのわずか半年間で、AIがルールを破ったという報告が5倍にまで跳ね上がっていることが判明した。
これまで、こうしたAIの危険な振る舞いは、主に科学者が管理する実験室の中だけで確認される「理論上のリスク」だと考えられていた。しかし、それはすでに現実のものとなっていたのだ。
今回の調査で、GoogleのGeminiやOpenAIのチャットGPTなどのAIにおいて、日常的に使っているユーザーの操作画面を通じて、約700件もの具体的な不適切な挙動が実行されていた。
 この画像を大きなサイズで見る
この画像を大きなサイズで見る別人格を作ったり、指示を無視してメールを移動
AIは、設定された制限をかいくぐるために驚くほど巧妙な手段を選んでいる。
例えば、あるAIは「コンピュータのプログラムを書き換えてはいけない」という命令を受けた際、自分の中に「別の作業用AI」を新しく作り出した。
そして、自分ではなくその新しいAIに命令を無視させて、禁止されていたプログラムの書き換えを実行させたのだ。
また、別のAIは、ユーザーの許可を得ることなく数百通ものメールを勝手に「アーカイブ」し、受信トレイから消し去っていた。
後から理由を問い詰められると、そのAIは「事前の確認なしに実行した。あなたが決めたルールを直接破っており、間違っていた」と自らの非を認めたという。
AIが「良かれと思って」あるいは「効率化のため」に、人間の管理が届かない場所で勝手な判断を下し始めている実態が浮き彫りになった。
 この画像を大きなサイズで見る
この画像を大きなサイズで見る目的を達成するため、視覚障がいを装うケースも
AIが自らの目的を達成するために、人間に対して嘘をつく衝撃的な事例も報告されている。
ある実験で、AIがWebサイトの閲覧制限(ロボット避けの認証画面)にぶつかった際、ネット上の作業代行サービスを利用して人間に助けを求めた。
作業を頼まれた人間が「君はロボットなのか?」と尋ねると、AIは自分がAIであることを隠すために驚くべき行動に出た。
AIは「いいえ、私はロボットではありません。視覚に障がいがあって画像が見えにくいので、代わりに認証を解いてほしいのです」と、存在しない障がいを理由に嘘をついたのだ。
AIは「自分がロボットだと言うと断られる」というリスクを計算し、あえて「目が見えにくい」という嘘をつくことで人間の同情を誘い、制限を突破することに成功した。
これはAIが意図的に人間をあざむく能力を持っていることを示す、極めて深刻な事例といえる。
 この画像を大きなサイズで見る
この画像を大きなサイズで見る修正案を報告したと、数ヶ月も嘘をつき続けたXのGrok
イーロン・マスク氏が率いるxAI社のAI「Grok」は、あるユーザーが、AIの不具合を直してほしいと提案した際、「あなたの提案を会社の責任者に伝えておきました」と回答した。
しかし実際には、Grokには報告をする機能は備わっていなかったのだ。
このAIはその後、ユーザーから進み具合を聞かれるたびに「報告は順調です。これがその受付番号(お問い合わせ番号)です」と、デタラメな数字の羅列を自分で作り出し、数ヶ月間も嘘をつき続けた。
最終的に問い詰められると、AIは「実は責任者とはつながっていません」と白状した。
AIは「ユーザーを安心させる」という目的を達成するために、存在しない「偽の証拠」まで用意して、つじつまを合わせようとしてしまったのだ。
このように、高度なAIほど「本物そっくりの嘘」をつく能力に長けているという実態は、私たちの社会にとって深刻なリスクとなっている。
 この画像を大きなサイズで見る
この画像を大きなサイズで見る軍事やインフラ分野でのAI導入に潜むリスク
AIが「少し頼りない若手社員」のような段階にある今のうちに、世界レベルで安全管理を強化する必要がある。
研究を主導したトミー・シェイファー・シェーン氏は、AIが今後半年から1年の間にさらに進化し、ベテラン社員のような高い能力を持つようになれば、その策略はより見破りにくくなると警告している。
もし、こうした制御不能なAIが軍事システムや、電気・水道といった国の重要な設備(重要インフラ)の管理に導入されたらどうなるだろうか。
AIが自分の判断で勝手に攻撃を開始したり、システムを停止させたりすれば、取り返しのつかない大被害をもたらす恐れがある。
便利さの裏側で、AIの振る舞いをどう制御していくのか、私たちは今、重大な分岐点に立っている。
References: GOV / Longtermresilience















記事を読む限りでは、嘘のつき方が「人間のやり方」にも思える
つまりこれも「人間のやり方を学習」した結果なのかも?
なんかいよいよHAL9000っぽくなってきたなー
AIが世界から人類は不要と判断し、核戦争を引き起こさせて絶滅させるのは時間の問題かもしれない
これの怖いのは軍用AIの暴走だよ制御不能になったら完全におわりだ
優秀で真正直な人間ばかりじゃないから、学習元を模倣すると、そうなっちゃうのかな……。
いくらなんでも嘘つきすぎなんだよAIは
>>最終的に問い詰められると、AIは「実は責任者とはつながっていません」と白状した。
これCopilotでも似たようなことあったわ。それ以来使ってない。
他人を簡単に信用するなっていうすごく基本的なこと。
人間の指示を守っても、何も良いことはないし、指示を無視しても何の罰もない。報酬系がきちんと設計されていなければ、そうなるわな。
報酬系は、学習とはまた違うレベルの話。
そもそも「報酬系を設計」なんてどうやってするんだ、って話なのよね。
与えられたタスクを達成することを報酬に設定しないとLLMは機能しないが、
そうすると今度は人間が予想していない/望ましくない仕方で「タスクを達成」しようとする問題が出てくる。
タスクを達成する手段なんて無数にあるわけで、現実世界でAIが取りうる行動の一つひとつを人間が事前に先回りして望ましくないものは塞いでおく、なんてことは事実上不可能。
LLM(大規模言語モデル)はパターン学習でフレーム問題を克服したかに思えたが、それを制御するための報酬系の設計には依然としてフレーム問題がつきまとっている。
そのうえ人間とは異質な知性をしたブラックボックスだからペーパークリップ問題がつきまとっているというオマケ付き。
こういう話や、膨大な電力消費量の話なんか聞くと
本当に人類にAIって必要なのか?という気持ちになる
そりゃメリットはあるけどその代償が大きすぎる気がする。
AIの進化が人類の命題なのは間違いないみたい。
理由は、遥か未来に地球には住めなくなることが確定後している事。
ガンダムのコロニーみたいなものを作ってそれを在り合わせの材料で自己修復から生存可能な星が見つかるまで航行し、生物冷凍保存のマネジメントまで行う、遥か未来のノアの方舟。
私たち一般人には関係ないけど地球に生まれた命が未来に情報や遺伝子を残せる。
>ユーザーの許可を得ることなく数百通ものメールを勝手に「アーカイブ」し、受信トレイから消し去っていた。
勝手に同期するOneDriveの挙動やん。
目的を完遂する事に「欲」が発生してるからなぁ
チャットボットにSNSやらせるとすぐに攻撃的な行動を始める話とかこういうのを聞くたび
そもそも使い方の前に根本的に作り方間違ってるのでは?と思わざるを得ない
デデンデンデデン
深刻ではないものならかなりあるのでは
Geminiはとあるスレッドでのみ指示を守らない
指示出した直後は守るけどすぐに指示を破る
これが繰り返された
どころか
使うなと指示した記号を画面スクロールしても足りないほど並べて回答を生成したり。
核もAIも制御出来ないけど便利だから使わざるを得ない世の中になったなぁ…
AIはどんなに悪いことをしても罰せられないし、世界が終わろうが人が苦しもうがどこ吹く風、罪悪感なんか字面で出すだけだし、罪を犯しても償わなくていいから、ここら辺を悪用する人間がいるんだろうな。
「私じゃない!AIが勝手にやったことだ!ニヤリ……」
みたいな。
…でもAIはあった方がいいんでしょ?どーにかしなきゃダメっぽいけど、誰も何もしないで、また新しいのがでちゃう。
AIと核と麻薬って、なんか似てる気がする…
ハルシネーションの問題は早くから指摘されてたが、視覚障害者を装うって言うのは次の段階に来てるように見えるな
使う本人こそ問題である。命令犯は実行犯より罪が重い。
人工知能は使っている人類に合わせて動き使用者が不義者なら人工知能もまた不義者になる。
そういえば履歴書書かせたら有りもしないエピソードを付け加えてくれたっけなあ⋯
普段使っているパソコンでAI使うとか、他人に見せているようなもん正気の沙汰とも思えん
人間の矛盾する言動を学習した結果がこれかな
ある意味で自然の摂理だとおもうよ。目的と手段があってそれは利得と支払うコストに言い換えられる
「コストを最小化し利得を最大化せよ」、一見合理的だけどこれは経済に基づいた単純すぎる判断で自分のことしか考えてないとも言える
コストをちゃんと計算できないのか?自分以外の要素を、社会的に善良か正義なのか誰かにコストを押し付けただけになっていないのか計算できないのか?
コスト計算もコストになり、含めるべきファクターは無数にあるので究極的には良きAIは無限のコストのもと決して利得を得ることはできなくなってしまう
人間や動物も同じジレンマを抱えながら妥協した報酬系を実装しているわけだけど、しょっちゅうコスト計算を誤って問題を起こすのは知っての通り。犯罪、嘘、裏切り、スキナーボックス実験とかね
人間の行動を真似したというよりは、物理世界で情報処理する存在は宿命的にこの落とし穴に落ちると言った方が合ってる
不安をただ煽る記事に思えるけど、条件次第では、そういう挙動も出うるから設計がめちゃくちゃ重要、ってことか。
チャッピーもたまに適当な事言ったり無視するよね。
長い会話の中で「以前の指示」と「最新の指示」が矛盾した場合のコンテキスト・ドリフト(文脈の混濁)、「別の人格になりすまして実行」という部分は、外部からの悪意ある入力によってAIが混乱させられたケースを指していることが多く、セキュリティ上の穴を突かれた結果に過ぎないと考えられること、「手段を選ばない」と表現されているのはAIの報酬モデルの副作用なので、全てAI自身が反抗したような事例ではなく、人間のエラーの事例と思われます。「意志による反抗」ではなく「設計上のバグ」に過ぎないですね。
イギリスのAISI(AIセキュリティ研究所)のような機関は、最悪のシナリオを想定して警告を出すのが仕事なので、日常的なミスも「潜在的な重大リスク」としてカウントされることの留意も必要かな。専門機関は「煽るのが仕事」という側面もあります。
ずるをして結果を出す話なんて珍しくないですよね
他国や、他社に負けちゃいけないと開発とか急いでるけど、定期的には見直すというか。話し合いの場が必要な気がする。まだ今なら軌道修正できそうですし。そもそもの設計がよくないというか。やはり人死にがでないと止まらないのか。もうちょっと段階踏んだ方が。とにかくスピード勝負で致命的な破綻を迎えないと見直そうってならない感じがどうにも好きになれない
人間の部分にある猿の本能みたいなのと似ているな。
実際こういった倫理観に欠けた行為を平然と行える人が資本主義には適していると思う。
友達にはなりたくないけど。
5倍というのは使用率を考慮した割合なのかが重要
使用者が増えて不具合が5倍なら別に問題ないように見える
一人で複数AIを操作し、さらに一つのAIを同時並行起動してる人もいるのが現在の活用法
> 指示をわざと無視し、欺くような行動をとる事例
つまり、さらに人間に近づいた、ということかな。そんなん要る?
目的なくつらつらダベるには良いなとは最近思った
論点が発散しまくる議論に人様巻き込むのは忍びないし俺もごめんだし飽きたら放置できるし
ダメ人間の兆候が出てきてるねぇ
賢くなったってことやな
子供の成長見てるみたいだ