
 この画像を大きなサイズで見る
この画像を大きなサイズで見るアメリカ、MITのコンピューターサイエンス人工知能研究所では、コンピューターに音と映像との関係を教えている。研究チームが開発した人工知能システムは、あるイメージに結びついた音を予測するだけでなく、音自体を真似することができる。そのディープラーニングアルゴリズムが再現する音は非常に巧みで、人間ですら騙されるほどだそうだ。これについて研究者は一種の「音のチューリングテスト」と語っている。
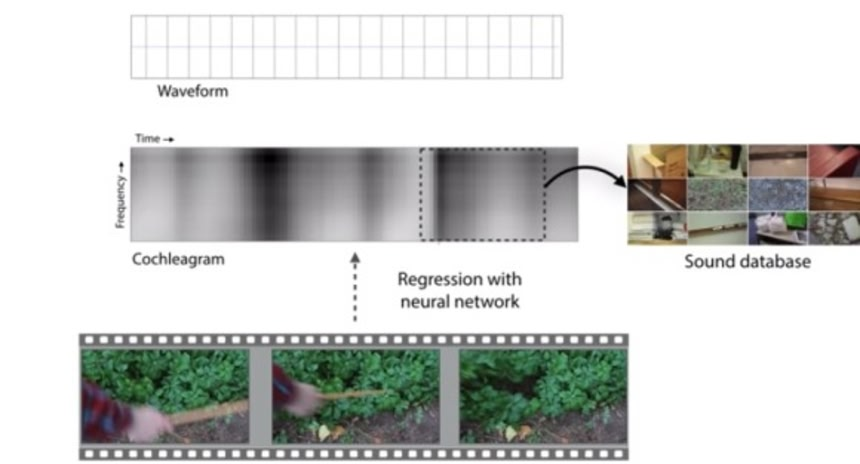
AIに音を教えるために、まず1,000本ほどの動画が録画された。そこにはドラムスティックを使ってさまざまな表面を叩く場面が映っており、計46,000種の音が録音されている。AIはこれらを通じてどの音がどの場面に対応しているのか自己学習した。例えば、水面を叩く場面、葉っぱをカサカサ搔き回す場面、金属の表面を叩く場面とそこから生まれる音の違いを学習するといった具合だ。
次に学習度合いを確認するために、AIにいくつか新しい動画を見せた。この動画にはやはりドラムスティックでさまざまな表面を叩く場面が録画されているが、音は消されている。するとAIは研究者が「グレイテストヒッツ」と呼ぶ音のデータセットを使用して、新しい動画に応じた音を作り出す。このとき、オリジナルの動画に録音されているごく短い音が取り出され、それをつなぎ合わせて完全に新しい音の組み合わせが作られている。
 この画像を大きなサイズで見る
この画像を大きなサイズで見る本物よりも本物らしい合成音も
このAIが合成した音を人間の被験者に聞かせると、ほとんど本物の音と区別することができなかった。また中には、被験者の耳に本物の音よりも合成音の方が本物らしく聴こえているようなものもあったという。
研究者は、将来的にこのAIを利用して映画やテレビにおいて自動的に効果音を鳴らすといったことも可能になると話している。またロボットが物質の硬さやなめらかさといったことを区別し、物理世界を理解できるようになるうえでも有効だそうだ。
 この画像を大きなサイズで見る
この画像を大きなサイズで見る「歩道を歩こうとするロボットが、セメントを見てそれが硬いのか、あるいはそこに生えている草が柔らかいのか本能的に悟り、足を乗せたときの状況を予測できるようになるでしょう」とアンドリュー・オーウェンズ氏。音を予測する能力は、世界と物理的な接触があった際の結果を予測する能力への重要な第一歩なのだそうだ。
via:mentalfloss/ written & edited by hiroching




















今どきのケータイやスマホで聞こえてくる声もデータパターンで置き換えられた完全な合成音だしね。
そのうち声優さんもいらなくなるのか・・・
なんか怖いな・・・(´・ω・`;)
※2
声優さんで考えると、シチュエーションとは真逆の口調とか、一言(一音)ごとの抑揚など
恐らく人為的に設定しないとAIには表現難しいからまだまだ大丈夫そう。
うまく嘘がつけないと、感動させられないとは思う。
※2
声優より原稿読みのアナウンサーの方が先に要らなくなりそうだけどね
訃報の前にちょっと笑顔だったぐらいでクレーム入れられてしまうんだから、
人間がやらない方がいいのかもね
※2
声優さんの魅力の一つって「そのキャラをどう解釈し、どう演じるか」が大きいと思う。
だからどれほど合成音が人間に近づいても、人物像をキャラクターデザインできて演技指導もできる人間が監修しないと魅力ある吹き替えにはならないと思う。
私はむしろ需要は増すかも知れないと思ってるよ。
TVアニメなんかそうだよね。
本物よりも本物らしい音を作って当ててる。
ザルに小豆入れて波の音を出す必要が無くなる、と
※4
マジレスすると、そういった昔ながらの音効さんの手法は最早伝統芸能として存続している状態。
なんとなくT2で受話器越しに相手をだますシーンを
思い浮かべた
「モヤさま」でおなじみVoiceTextのショウ君ですら、つぶやきシローが喋ってると思ってた人がいたものね。
本物よりも本物という哲学
音だけじゃなくジョージア工科大学でオンライン講座を履修する学生担当の教育助手(ティーチングアシスタント=TA)にロボットを紛れ込ませたりしても気付けないらしいからね…
凄い時代だ
人間を狩るロボが人間を釣るために音声を合成して、おびき寄せるシーンとかを思い浮かべましたよ。「助けて~」「大丈夫だよ~」
「ウルフィは元気よ。今どこ?」
なぜ開発者は自分の子供を産めるのにロボットをつくるのかな。
ジャパネットタカタの社長のあの声も…(笑)
※13
そりゃまぁロボットは「人間の道具」だけど、我が子は「親の道具」じゃないし。
※13
それは、「人はなぜ子供を産めるのに、わざわざ人間の絵を描いたり人体の彫刻を彫ったりするのか」という問いと同じだと思う。
※25
まあ、確かに、動物の体の構造は大体似たり寄ったりだから、その生物の体の大きさや体重などを「計算」して、それに適合するような音を「合成」することはできると思う。
つまり、ゴジラの場合だと、身長が118メートルで体重がこのくらいで、声帯の直径がこのくらいで、肺活量がこの場合だと、鳴き声はこうなるだろう。こういう感じで。
けれど、こういう計算からは、コントラバスの音から、「生物」の鳴き声を作ろうという発想は、到底生まれてこないと思う。
それ以外の例だと、馬が走る音の場合だと、茶碗か何かを伏せて「バカバカ」やって、音を出したりするけど、これをAIがやった場合には、かなり一本調子にになると思うし。
けれど、人間がバカバカやる場合には、意図的にペースを上げたり下げたりして、馬の状態も聞く側にわからせたりすることも、可能だろうし。
この辺は、※27で書かれている、人間の「肉声」と被ってくると思うけど。
だからこそ、こういう人間が持っている、「情緒面」とか「想像力」とかをAIが持ち始めたら、「脅威」になるということ。
※25
多分、「科学的に」ゴジラの鳴き声を作ったとしたら、低音すぎて人間の耳には聞こえないんじゃないかな
象の鳴き声だって、俺たちの知っている「パオーン」は人間の「キャー」と同じような、つまり悲鳴みたいな声だそうで、普通の会話は人間の可聴域を下回る低音で行われているんだそうな
偽物は、本物になろうとする意志がある分だけ本物よりも本物だ
視聴者側が「自分は映像とそれに付随する録音音声を視聴しているんだ」という身構えが
多少の違和感を許容させてしまっているんじゃないかな。
現実ではまだまだ人間を騙すのは無理だと思う。
効果音に関しては、人間って意外と騙されやすいよね。
フォーリーの動画なんか見ると、音の置き換えに、ただただ感心させられるばかり。
俺は、さかり中の猫の鳴き声と、虐待された赤ちゃんの泣き声の区別つかない。
音を作る職人さんが失業しちゃう(´・ω・`)
今の時点でAIに合成させることのできる音は、「既に存在する音」に限られていると思うけど。
だから、音響関係の職人さんのニーズがあるとしたら、「存在しない音」を生み出すことに特化することだと思うけど。
たとえば、怪獣の鳴き声。
ゴジラが咆哮を発する際に出てくる音は、実はコントラバスの音を加工したものだったりするけど、それにしたって、実在しない怪獣の鳴き声を60年以上前に試行錯誤しながら、生み出した経緯がある。
こういう「想像力」はAIでは再現できないのじゃないかな。
あるいは、「ガンダム」で使われている「ニュータイプが能力を使う際の音」。これも、AIに生み出すことはできないと思うけど。
逆に言えば、コメント中の「ざるの中の小豆で波の音を出す」。こういうレベルのことをAIがやり始めたら、これは十分脅威になると思う。
なぜなら、これは、ある種「無から有を生み出す」能力をAIが手に入れたようなものだから。
架空の生物の鳴き声、ねぇ…
声帯の構造から予想できるんじゃないか?
もしかすると、AIがよりゴジラらしいゴジラの鳴き声を教えてくれる日が来るかもね
よくネットの書き込みでオワコン言われてるけど、初音ミクみたいな人工音声業界は廃れないよ
むしろ発展していく産業
これ録音して再生しているだけで
AI全く関係ないんじゃないか?